Kalmar
 ARM64-Cluster
ARM64-Cluster
Motivation
Bei einem Kundenprojekt ging es darum, auf einem Linux-PC eine Software zu entwickeln, die am Ende auf einem embedded ARM64-System laufen sollte. Der Entwicklungsablauf sah in etwa so aus:
- C++-Quellcode auf dem PC schreiben
- Nativ für den PC kompilieren und testen
- Wenn das einigermaßen erfolgreich war
- Für ARM64-System kompilieren, auf das Zielsystem aufspielen und testen
- Weiter bei 1
Da das ARM64-System ein Linux-System ist, ergab sich die Frage, was wäre, wenn man direkt auf einem ARM64-System entwickeln würde. Der Workflow wäre drastisch gekürzt:
- C++-Quellcode auf dem ARM64-System schreiben
- Nativ für ARM64 kompilieren und testen.
- Weiter bei 1
Software
Allgemeines
Allerdings ergeben sich die beiden Probleme, dass einerseits die CPU-Leistung eines embedded ARM64-Systems deutlich geringer ist als die eines aktuellen PCs und andererseits ebenso die Speicherausstattung. Moderne C++-Entwicklungsumgebungen benötigen eine ganze Menge RAM für ihren Index und was nicht noch alles. Ein nativer Compiler dagegen läuft im Allgemeinen schon mit recht wenig Speicher, zumindest wenn keine besonderns aufwändige Templateverarbeitung dabei ist. Das ist tatsächlich nur an den wenigsten Stellen in typischen Projekten so, der überwiegende Teil der Quellen ist recht simpler Code.
Da die CPU-Leistung stark begrenzt ist, müssen eben viele CPUs zum kompilieren herangezogen werden. Ältere Experimente mit distcc hinterließen bei mir einen guten Eindruck, was die Skalierbarkeit gegenüber lokalem make betrifft: Fast 1! Also müssen es distcc-Knoten werden, mit einem als zentralen client. Ziel ist es, bei der Softwarekonfiguration so nah wie möglich an verbreitete Linux-Distributionen heranzukommen. Daher sollte es nach Möglichkeit ein reines Debian ARM64 sein oder ein nahes Derivat.
Versionen
Die Testrechner liefen mit Debian Stretch, linux-3.14.79 (ARM64) bzw. linux-4.9.0 (x86-64), gcc-6.3.0, distcc-3.1, GNU make 4.1, ninja-1.7.2 Compiliert wird jeweils blender-2.78.
Hardware
Rechenknoten
Es stehen mehrere günstige ARM64-Einplatinenrechner zur Verfügung. Modelle mit 1 GB RAM werden erst mal nicht in Betracht gezogen, in die engere Auswahl kommen Banana-Pi M64, Odroid C2 und Rock64. Die folgende Tabelle listet die relevanten Unterschiede auf.
| Banana Pi M64 | Odroid C2 | Rock64 | |
|---|---|---|---|
| CPU | 1.2 Ghz Quad-Core ARM Cortex A53 | 1.5 Ghz Quad-Core ARM Cortex A53 | 1.2 Ghz Quad-Core ARM Cortex A53 |
| RAM | 2 GB | 2 GB | 4 GB |
| Flash | Micro-SD, EMMC 8 GB | Micro-SD, EMMC bis 64 GB | Micro-SD, EMMC bis 64 GB |
In diesem ersten Testaufbau entscheide ich mich für 8 Knoten Odroid C2. Zusätzlich werde ich noch einen Rock64 zum Vergleich heranziehen.
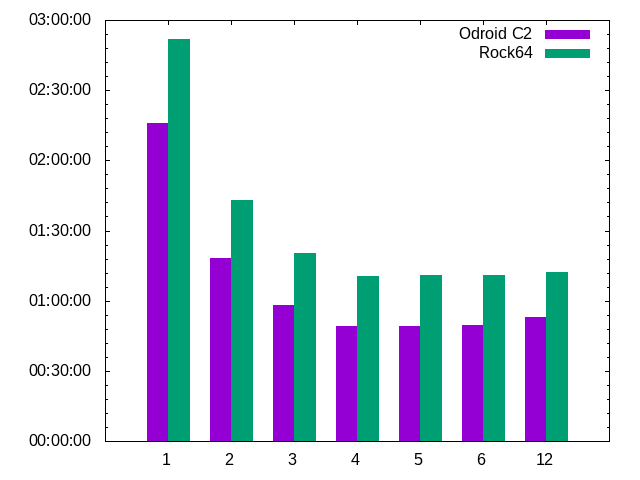 Das sind die Real-Compilezeiten für Rock64 und C2, jeweils mit 1..6 parallelen Prozessen, erreicht mit make.
Der C2 ist immer schneller als der Rock64. Daher war meine Anfangsidee, auf den C2 zu setzen, gleich mal richtig. Das muss
allerdings nicht in jeder Umgebung so sein. Um das zu prüfen, ist der Vergleichswert mit 12 Prozessen da, der mal den RAM
soweit ausnutzen sollte, dass der Rock64 schneller ist als der C2, der SWAP-Speicher nutzt. Dazu ist es allerdings nicht
gekommen, auch 12 Prozesse passen in 2 GB RAM. Aber 12 Prozesse bei 4 Kernen wird realistisch sowieso kaum auftreten.
Zumindest für Blender lässt sich sagen: Der C2 ist immer schneller als der Rock64. Umd mehr als 4 Prozesse bringen
auch nichts auf diesen Vierkernern.
Das sind die Real-Compilezeiten für Rock64 und C2, jeweils mit 1..6 parallelen Prozessen, erreicht mit make.
Der C2 ist immer schneller als der Rock64. Daher war meine Anfangsidee, auf den C2 zu setzen, gleich mal richtig. Das muss
allerdings nicht in jeder Umgebung so sein. Um das zu prüfen, ist der Vergleichswert mit 12 Prozessen da, der mal den RAM
soweit ausnutzen sollte, dass der Rock64 schneller ist als der C2, der SWAP-Speicher nutzt. Dazu ist es allerdings nicht
gekommen, auch 12 Prozesse passen in 2 GB RAM. Aber 12 Prozesse bei 4 Kernen wird realistisch sowieso kaum auftreten.
Zumindest für Blender lässt sich sagen: Der C2 ist immer schneller als der Rock64. Umd mehr als 4 Prozesse bringen
auch nichts auf diesen Vierkernern.
Netzwerk
Alle Rechenknoten verfügen über Gigabit-Ethernet. Der Testaufbau wird einen 100Mbit-Switch ausgestattet, in einem späteren Test mit einem Gigabit-Switch. Es soll damit ermittelt werden, ob die 100 Mbit einen Flaschenhals darstellen.
Spannungsversorgung
Der Odroid C2 bekommt seine Versorgungsspannung über Micro-USB. Hardkernel empfiehlt ein 2,5 Ampere-Netzteil für die 2 GHz-Version, im Headless-Betrieb und mit 1,5 GHz sollten 2 A reichen. Für 8 Knoten müssen es also 16 Ampere sein. Die Wahl fällt auf 2 5-Fach-USB-Netzteile von Revolt mit jeweils 8 Ampere Ausgangsbelastbarkeit.
Mechanik
Für den Testaufbau soll es Material aus dem Baumarkt sein. Testaufbauten müssen rustikal wirken. Ein paar Schrauben, Leimholzplatten und Kanthölzer bilden das Gehäuse.
Messwerte
Make und 1..8 Knoten
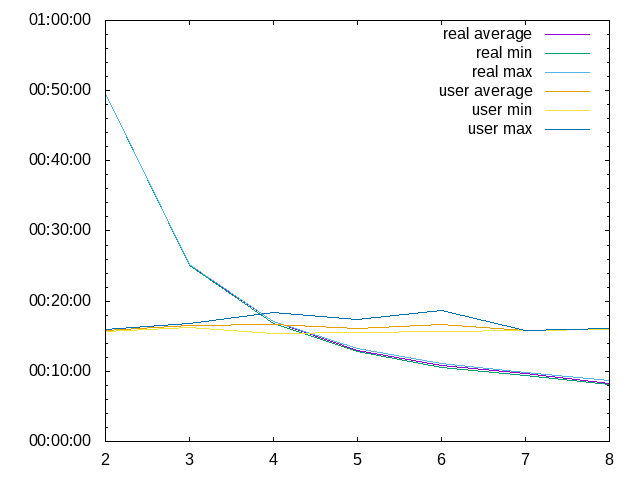 Die Zählung beginnt bei 2, da ich mir hier den Luxus leiste, einen Knoten allein für das Verteilen der Compile-Jobs
zu reservieren. Dementsprechend sind 2 Knoten auch ungefähr so schnell wie einer, auf dem alles lokal läuft.
Es wurden 4 Prozesse pro Knoten gestartet.
Die Zählung beginnt bei 2, da ich mir hier den Luxus leiste, einen Knoten allein für das Verteilen der Compile-Jobs
zu reservieren. Dementsprechend sind 2 Knoten auch ungefähr so schnell wie einer, auf dem alles lokal läuft.
Es wurden 4 Prozesse pro Knoten gestartet.
Entscheidend sind hier die real-Zeiten. Da die Abweichungen min/max/average sind nur sehr klein.
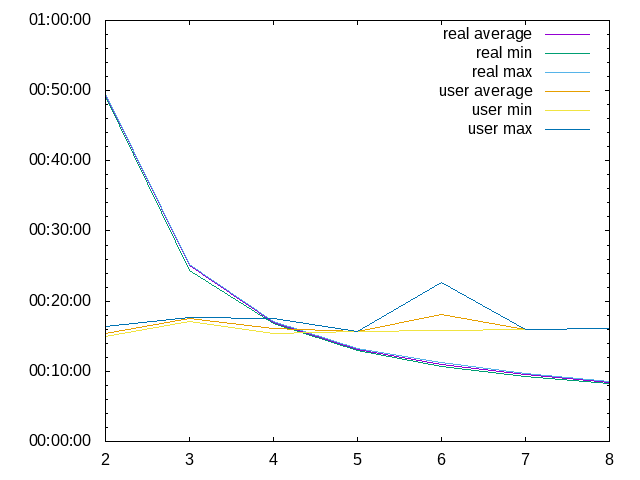 Mit 6 Prozessen pro Knoten gibt es eine starke Abweichung vom Durchschnitt bei 6 Knoten in der user-Messung. Entscheidend ist hier wieder die real-Zeit.
Mit 6 Prozessen pro Knoten gibt es eine starke Abweichung vom Durchschnitt bei 6 Knoten in der user-Messung. Entscheidend ist hier wieder die real-Zeit.
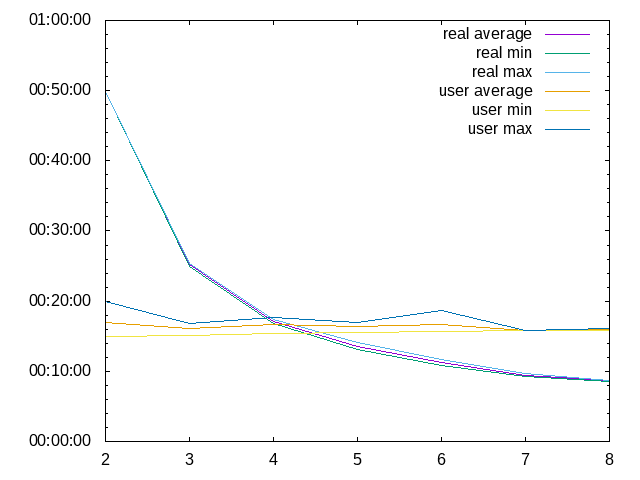 Mit 4 Prozessen pro Knoten mit distcc-pump.
Mit 4 Prozessen pro Knoten mit distcc-pump.
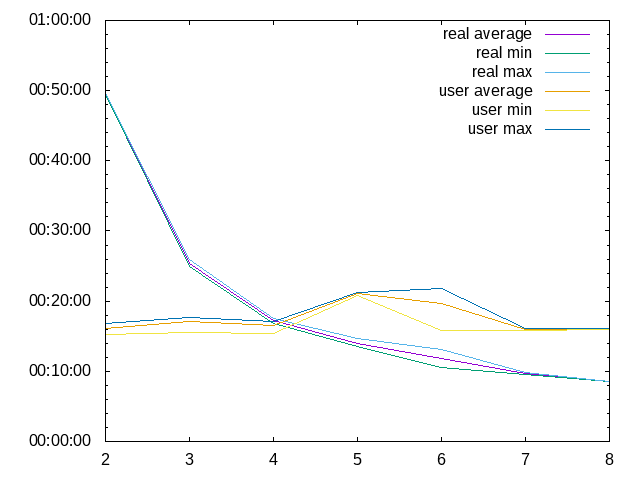 Und 6 Prozesse pro Knoten mit distcc-pump.
Zum Vergleich 4/6-Prozesse und distcc im plain-Mode und im pump-Mode, hier nur die durchschnittlichen real-Zeiten:
Und 6 Prozesse pro Knoten mit distcc-pump.
Zum Vergleich 4/6-Prozesse und distcc im plain-Mode und im pump-Mode, hier nur die durchschnittlichen real-Zeiten:
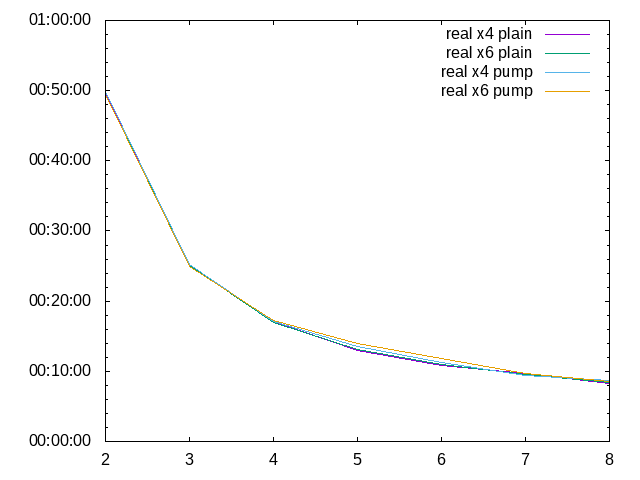 Die Abweichungen sind ausgesprochen gering. Die Schlussfolgerung daraus: mit make kann man es bei 4 Prozessen pro Knoten
belassen und distcc geht auch ohne Leistungseinbußen im plain-Mode.
Die Abweichungen sind ausgesprochen gering. Die Schlussfolgerung daraus: mit make kann man es bei 4 Prozessen pro Knoten
belassen und distcc geht auch ohne Leistungseinbußen im plain-Mode.
Vergleich mit Rock64
Da ich den Rock64 schon mal da habe, kann ich ihn auch mal probehalber in den Cluster einsetzen. Szenarien, die hier geprüft werden sollen, sind: Wie wirkt sich ein weiterer Knoten aus? Wie wirkt es sich aus, wenn man einen C2 durch einen Rock64 ersetzt? Als Client oder als Server?
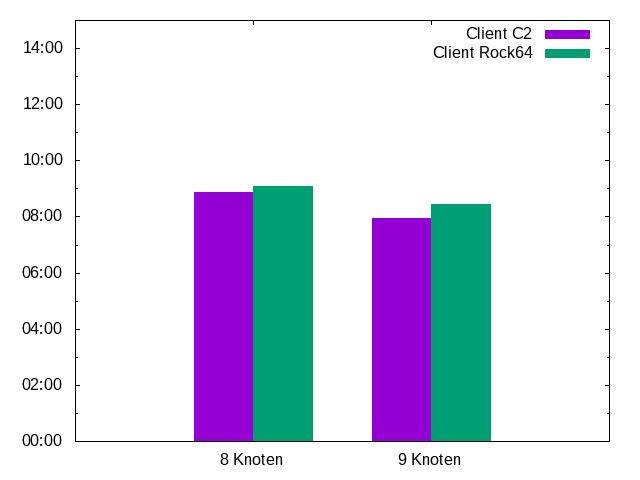 Der Rock64 ist als Server besser zu gebrauchen denn als client - die Compilierung wird durchweg schneller fertig, wenn
ein C2 der Client ist. In diesem Fall ist der Rock64 immer unter den Servern.
Der Rock64 ist als Server besser zu gebrauchen denn als client - die Compilierung wird durchweg schneller fertig, wenn
ein C2 der Client ist. In diesem Fall ist der Rock64 immer unter den Servern.
ninja statt make
Blender hat rund 3000 Dateien, welche compiliert werden müssen. Interessant ist die Frage, ob Ninja den Weg durch diese Abhängigkeiten besser findet als make. Dazu wurde der 9-Knoten-Cluster verwendet, mit wahlweise C2 oder Rock64 als Client.
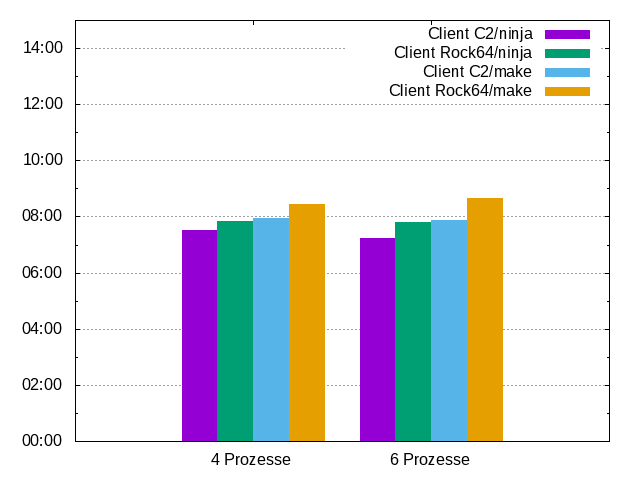 In diesem Setup ist man mit ninja deutlich (mehr als eine halbe Minute) schneller als mit make.
In diesem Setup ist man mit ninja deutlich (mehr als eine halbe Minute) schneller als mit make.
Vergleich mit x86
Bevor manch einer jetzt denkt, man hätte es hier mit einem Supercomputer zu tun, folgt als Vergleichsmessung noch diverse x86-PCs, die alle nicht die schnellsten sind.
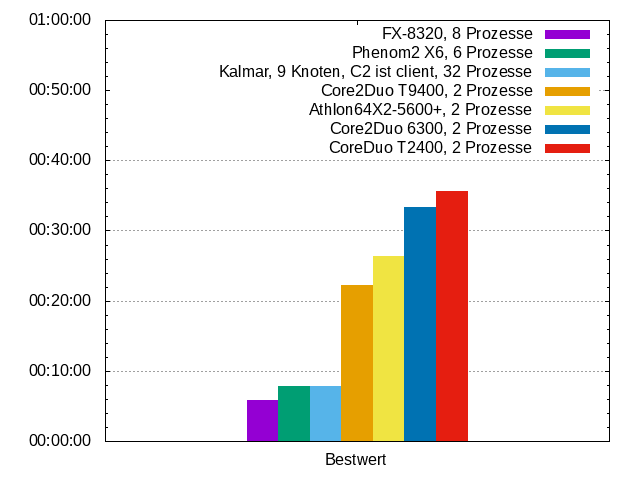 Mit make als Buildsystem ergibt sich, dass der 9-Knoten-Kalmar mit einem Odroid C2 als Client fast genauso schnell ist wie ein
Phenom2X6-1055T. Die AMD-Rechner wurden dabei im x86-64-Mode betrieben, die Intel-Rechner im i386-Mode.
Mit make als Buildsystem ergibt sich, dass der 9-Knoten-Kalmar mit einem Odroid C2 als Client fast genauso schnell ist wie ein
Phenom2X6-1055T. Die AMD-Rechner wurden dabei im x86-64-Mode betrieben, die Intel-Rechner im i386-Mode.
Ausblick
Anfang 2018 wurden einige Einplatinenrechner mit dem größeren SoC Rockchip RK3399 angekündigt. Ein zweiter Cluster mit 8 solcher neuen Knoten wartet auf Realisierung…